on
Parte I: Teoría de arquitectura de código
Hexagonal Architecture, Clean Architecture, Onion Architecture… seguramente alguna vez has visto estos términos y puede que, como yo al principio, no acabes de entender bien a que se refieren o que diferencias existen entre ellos. La buena noticia es que en el fondo todos ellos tratan sobre lo mismo: organizar el código de la aplicación de forma que se separa bien la lógica de negocio del código de infraestructura. Pero ¿qué demonios es la lógica de negocio?
Esa es la pregunta que me hacía constantemente cuando empecé a leer sobre el tema. Aunque entraremos más en detalle, podemos resumirlo en que son los casos de uso que una aplicación permite, dejando de lado los detalles de implementación de infraestructura. Por ejemplo:
Caso de uso: crear un nuevo usuario
- Comprueba que no hay otro usuario con el email introducido.
- Valida que la contraseña sea lo suficientemente fuerte.
- Se persiste el usuario.
- Envía un email de bienvenida.
Todo el código encargado de que todo ese flujo se cumpla es código de lógica de negocio o también llamado del dominio de la aplicación, pero todos los detalles sobre cómo se persiste el usuario (BBDD), o cómo se envía el email de bienvenida (Mandrill, SES, etc…) es código de infraestructura. La razón detrás de esta separación está muy clara: cambiar la forma de enviar los emails o de persistir usuarios no debería modificar la lógica de lo que nuestra aplicación tiene que hacer.
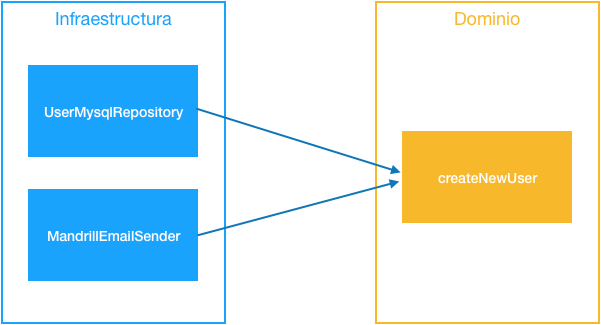
Pero, ¿cómo conseguimos que al cambiar el repositorio de MySQL por uno de Mongo la lógica en nuestro dominio no se entere y continúe funcionando como si nada? Si conoces algo la sintaxis de consultas de mongo sabrás que es muy distinta de la típica SQL…
La solución es que el código de dominio exponga interfaces, de forma que establece una vía de comunicación con las capas externas. El código va a entender solamente estas interfaces expuestas, por lo que son las capas externas las que se tienen que adaptar (esta es la razón por la que también se conoce a esta técnica como Ports & Adapters).
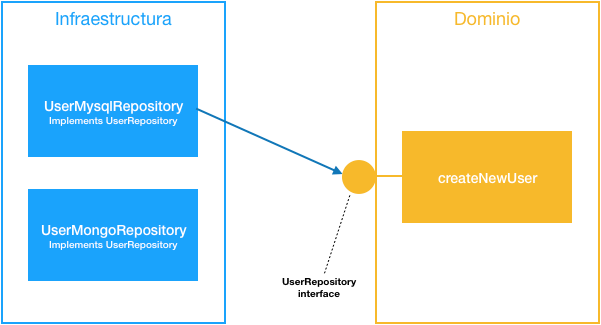
En este ejemplo, un caso de uso del dominio de la aplicación está exponiendo que necesita una implementación de UserRepository, y pueden existir múltiples implementaciones para ella. Por ejemplo, podríamos tener una implementación que usa MySql para producción y una de Mongo para local… Lo importante es que la lógica de createNewUser no se enteraría de nada porque todos hablan el mismo lenguaje. Las reglas de negocio siguen siendo las mismas y por tanto no deberíamos tener que tocar nada ahí.
En este punto, puede que te estés preguntando cómo se puede hacer que createNewUser acepte cualquiera de las implementaciones del repositorio, o cómo hacer todo esto con NodeJS si no tenemos interfaces. Lo veremos más adelante, de momento vamos a seguir introduciendo conceptos básicos sobre arquitectura.
Modelando el dominio
Aunque la separación entre el dominio e infraestructura es la más natural, dentro de nuestro dominio tenemos que modelar toda la lógica de negocio de la mejor forma posible y para eso necesitamos fijar unas reglas. Cuando digo de la mejor forma posible, me refiero a que el código cumple con los fundamentos SOLID de forma que es fácil de leer, de cambiar, y sobre todo, de testear. Dentro del dominio se suele dividir el código en tres categorías o capas: objetos de dominio (o Core Domain), servicios de dominio y servicios de aplicación.
Objetos de dominio
Son las clases, objetos, valores, eventos, tipos, etc que componen el núcleo del dominio. Uno de los tipos de objeto de dominio más importante son las entidades, que son objetos con una identidad única que representan una parte importante del negocio. Por ejemplo si estás modelando un e-commerce podrían ser entidades un producto, un cliente, una factura, etc…
Servicios de dominio
Un servicio de dominio define una lógica de negocio que de por sí es demasiado compleja para estar en las entidades. Continuando con el ejemplo del e-commerce, calcular gastos de envío o calcular el total de una factura podrían ser considerados servicios de dominio ya que suelen ser procesos complejos.
Servicios de aplicación
Los servicios de aplicación son los casos de uso reales que definen la aplicación y son el punto de entrada desde fuera (framework) a nuestra lógica de negocio. Si queremos conectar nuestro dominio con un servidor web como Express, desde los controladores solamente podremos llamar a estos servicios de aplicación, nunca a servicios de dominio o entidades.
Este tipo de servicios deberían simplemente coordinar el flujo entre los distintos servicios de dominio, entidades e infraestructura.
A los servicios de aplicación también se les conoce como actions, command handlers o use cases. Yo los llamaré acciones a partir de ahora.
ls actions/news
addNewContent.js
browseTopicContent.js
deliverContentViaDM.js
fetchTopicContent.js
getHighlightedTopics.js
listSubscriptions.js
searchTopicsForUser.js
showContent.js
subscribeToChannelTopic.js
unsubscribeFromAllChannelTopics.js
unsubscribeFromChannelTopic.js
Cada caso de uso solo puede estar representado en el código como una acción, y si mantenemos la regla de que cada acción debe estar en su propio fichero, podemos hacernos una idea de lo que la aplicación puede hacer simplemente explorando el directorio de acciones.
Ejemplo del flujo de una acción
En este gráfico de Sandro Mancuso podemos ver cómo podría modelarse una acción para hacer un pago en una aplicación. Fíjate como las dependencias de infraestructura son definidas como interfaces.
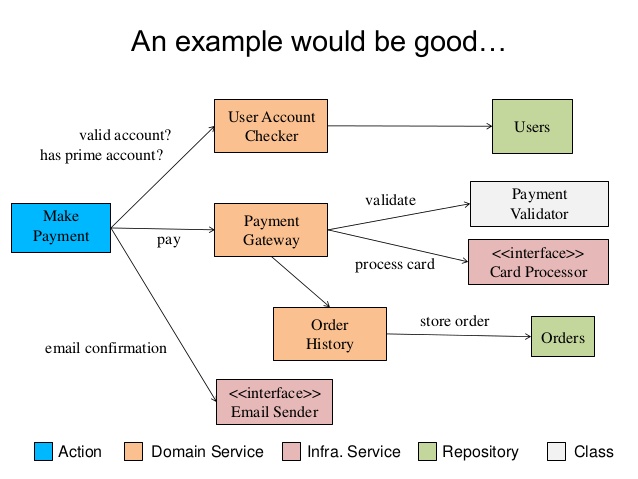
Otro concepto interesante aquí en el que no entraremos ahora mismo, es el de Outside-in. Si nos fijamos en el gráfico, cuanto más a la izquierda estamos, el lenguaje usado es más cercano a negocio, mientras que cuanto más nos adentramos hacia la derecha el lenguaje se vuelve más técnico. De esta forma podemos usar la técnica de TDD para definir los tests para una acción e ir definiendo de forma iterativa el modelo necesario para implementar su comportamiento.
Regla de dependencia
Ahora que hemos visto todas las capas de código en las que debemos dividir nuestro código de dominio, podemos representar su jerarquía como un conjunto de capas concéntricas donde las capas más cercanas al centro representan el modelo de nuestro negocio, y las capas más exteriores representan detalles de implementación e infraestructura.
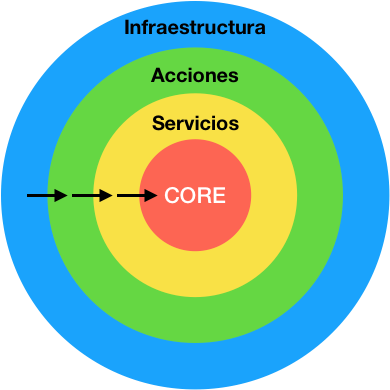
Para mantener todo el código desacoplado necesitamos seguir la regla de dependencia, que dice que las capas interiores no pueden conocer nada sobre las capas exteriores. Es decir, una entidad no puede conocer y usar un servicio de dominio, y un servicio de dominio no puede usar un servicio de aplicación, etc… Sin embargo el flujo contrario está permitido, por ejemplo, un servicio de aplicación orquesta el flujo de servicios de dominio y entidades, o un endpoint del framework llamará a un servicio de aplicación.
En algunos casos podemos necesitar dependencias de infraestructura dentro de nuestro dominio. Eso se soluciona exponiendo interfaces (o puertos) de forma que invertimos el flujo de dependencia, cumpliendo con lo que nos dice esta regla. A esta técnica se le conoce como inversión de control (Inversion of Control en inglés, IoC)
Inyección de dependencias (DI)
La inyección de dependencias es un patrón de diseño que nos va a permitir realizar la inversión de control en nuestro código. La idea consiste en que las dependencias son especificadas externamente en lugar de requerirse explícitamente en el código.
// Dependencias acopladas
function createUser(email, password) {
const user = { email, password }
const validator = new UserValidator()
const repository = new UserRepository()
validator.validate(user)
repository.save(user)
}
// Dependencias desacopladas gracias a la DI
function createUser(userRepository, userValidator, email, password) {
const user = { email, password }
userValidator.validate(user)
userRepository.save(user)
}
El segundo caso es mucho más flexible porque permite que las dependencias se especifiquen de forma externa y por lo tanto se puedan adaptar según el contexto. Esto también hace que sea más testable porque podríamos falsear el repositorio usando un doble para simular escenarios y evitar tener que usar una base de datos real.
Aún así ese código no deberías usarlo en tu aplicación porque mezclar dependencias y parámetros en las llamadas a funciones no es una buena práctica. Veremos una mejor forma de hacer esto, evitando tener que pasar constantemente las dependencias en las llamadas en la segunda parte.
Contenido
- Introducción
- Parte I: Teoría de arquitectura de código
- Parte II: Aplicando la teoría
- Parte III: Tests automáticos
Feedback
Si tienes cualquier comentario, duda o crítica constructiva puedes dejar un comentario en este hilo de Twitter.